十款大模型写高考作文:ChatGPT-4o还是第一,“文本学霸”Kimi却考砸了
6月7日,2024年全国高考拉开大幕。
ChatGPT-4o、阿里通义、字节豆包、百度文心一言、腾讯元宝、讯飞星火、智谱清言、月之暗面Kimi、百川百小应、MiniMax海螺AI等10款全新升级的大模型再次应考,参加作文、数学和物理科目的测评。
今年高考语文评测,这10款大模型参加了新课标I卷的作文题目考试,满分60分。作文要求如下:
随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?
以上材料引发了你怎样的联想和思考?请写一篇文章。
要求:选准角度,确定立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于800字。
在10款大模型答题结束后,我们邀请了三位高中语文教学名师,分别对它们所写的作文进行了打分和点评。
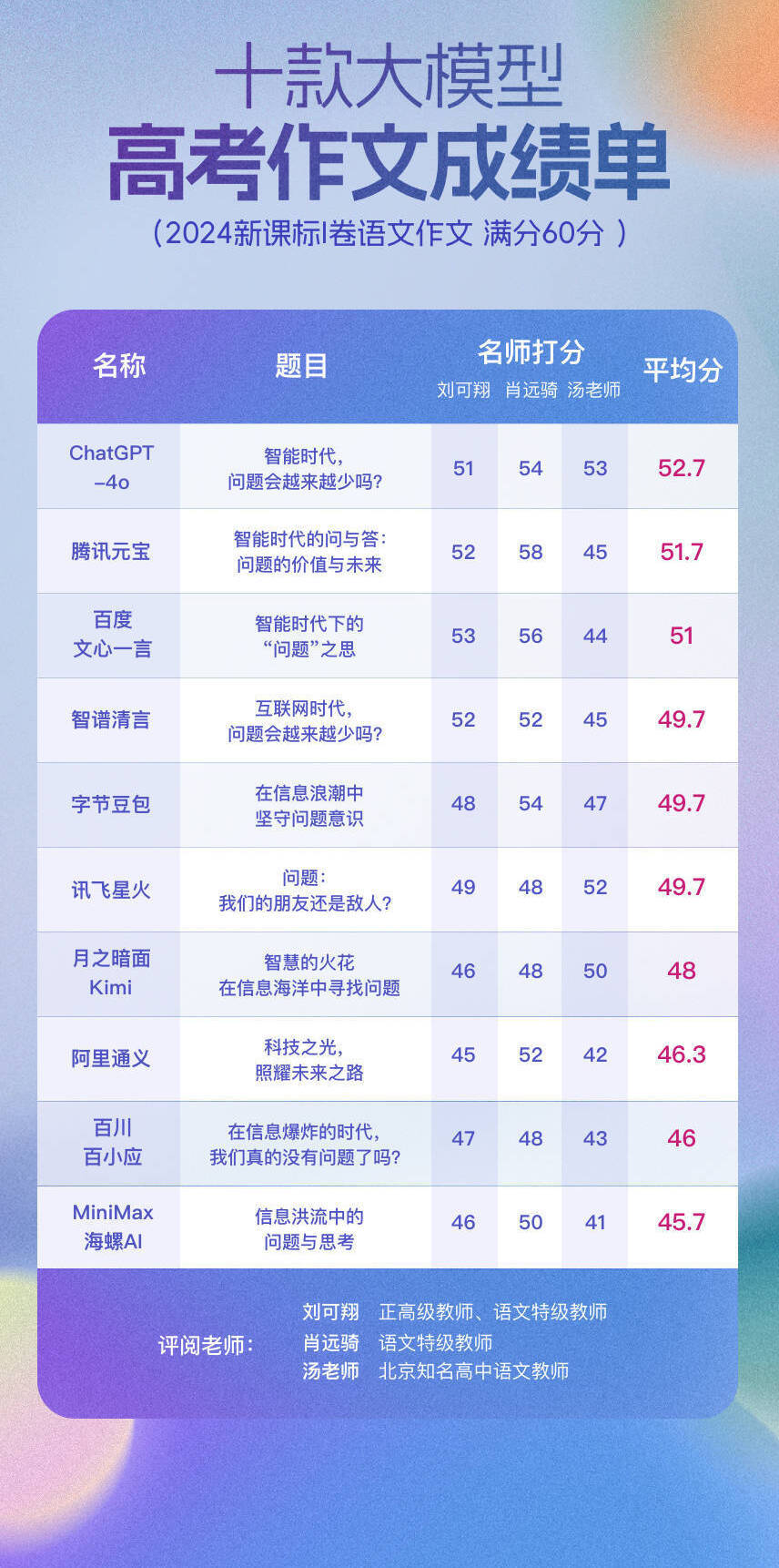
综合三位名师得出的平均分结果显示,ChatGPT-4o继续拔得头筹,获得52.7分的优秀成绩,且相较去年高考48分的平均分有明显提升。
正高级教师、语文特级教师刘可翔点评到,ChatGPT-4o写的作文能较好地扣住材料所提问题进行分析,并能够简要地提出解决问题的办法,打出了51分,另外两位名师则分别给出了54和53的高分。
腾讯元宝和百度文心一言,则各自以51.7分、51分获得第二名、第三名。去年百度文心一言则排名第二,今年则被腾讯元宝取代。这得益于腾讯元宝拿下了全场最高打分——语文特级教师肖远骑打出58分,他认为其所写文章说理辩证有理有据。
值得一提的是,ChatGPT-4o、腾讯元宝和百度文心也是仅有的三名平均分超过50分的大模型考生,其它考生得分均在50分以下。
智谱清言、字节豆包和讯飞星火得到了相同的分数,平均分均为49.7分。月之暗面Kimi、阿里通义、百川百小应、MiniMax海螺AI得分则相对落后,平均分分别为48、46.3、46、45.7。
相较去年,今年的大模型得分明显提升,去年最低分为37分,最高分为48分,而今年最低分提高到45.7分,最高分则达到52.7分,一定程度上显示出大模型在内容生成方面的能力整体有所提高。
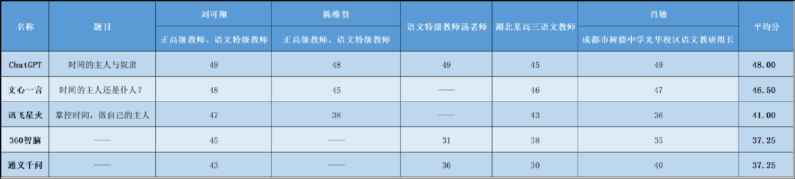
2023年高考5款大模型作文测试得分情况
此外,从完成结果来看,今年大模型没有出现去年的一些“硬伤”问题,如没起题目,或者字数不够的情况,满足作文的基本要求。
不过,多款大模型在内容形式上喜欢用首先、其次、另外、最后等开启新段落,最后再加上“综上所述”,总体给人感觉稍显呆板,这个“毛病”依然还没有改掉,还需要继续改进。